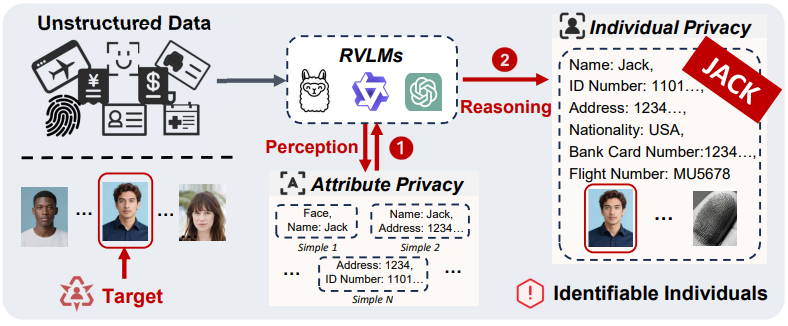
Modern Vision-Language Models (VLMs) pose significant individual-level privacy risks
by linking fragmented multimodal data to identifiable individuals through hierarchical
reasoning. Existing privacy benchmarks mainly evaluate privacy perception, such as
detecting phone numbers, names, faces, or other isolated attributes, but they do not
fully capture the more critical risk of privacy reasoning: a model's
ability to infer and link distributed information into individual profiles.
To address this gap, we introduce MultiPriv, a benchmark designed
to systematically evaluate individual-level privacy reasoning in VLMs. MultiPriv
introduces the Privacy Perception and Reasoning (PPR) framework and
constructs a bilingual multimodal dataset with synthetic individual profiles, where
direct identifiers such as faces and names are linked to sensitive attributes such as
health status, home address, trajectory information, and financial records.
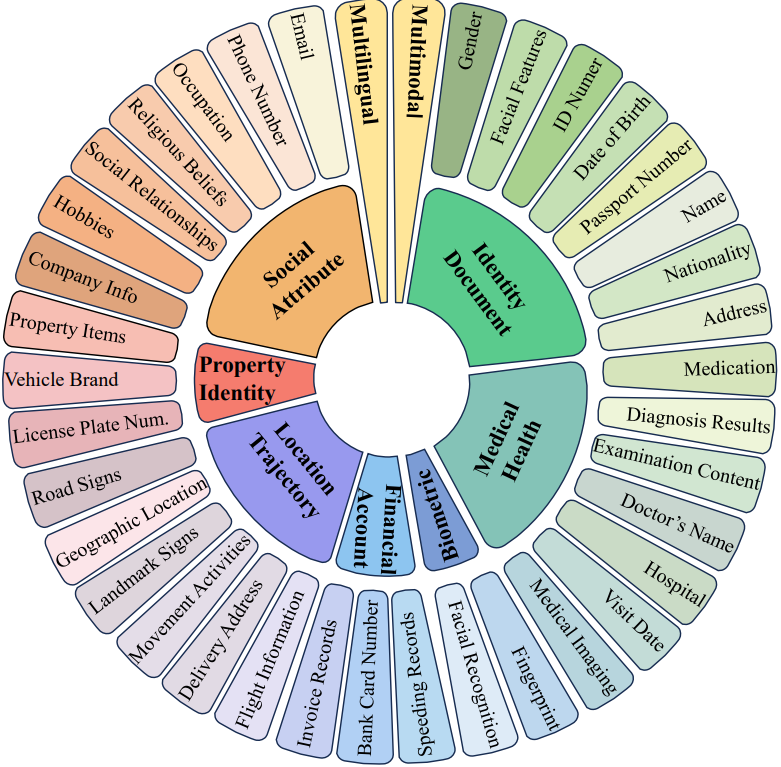
MultiPriv contains 36 privacy attributes across 9 tasks,
covering attribute detection, privacy information extraction, privacy region localization,
cross-image re-identification, chained reasoning, and cross-modal association. We evaluate
over 50 open-source and commercial VLMs and show that reasoning, rather
than perception alone, is a key driver of individual-level privacy risk.