学术定理性结论记录
学术论文阅读结论记录
阅读论文过程中,别人的一些结论进行记录,在自己工作中进行引用
差分隐私
- 在NLP任务中 DP模型的accuracy非常高 鼓励了privacy在语言模型的应用 (与之相对的是CV中DP会产生非常大的accuracy恶化 比如cifar10目前DP限制下只有80%accuracy 而不考虑DP可以轻松95%;ImageNet当时最好的DP accuracy不到50%)
- 在语言模型上 模型越大性能会越好 比如GPT2中 从4亿参数到8亿参数性能提升很明显 也取得了很多SOTA(但是在CV和推荐系统中 很多时候更大的模型性能会很差 甚至接近random guess 比如CIFAR10的DP best accuracy此前是由四层CNN得到的 而非ResNet)
- 在多个任务上取得SOTA的超参数是一致的 都是clipping threshold要设置的足够小 并且learning rate需要大一些(此前所有文章都是一个任务调一个clipping threshold 费时费力 并没有出现过像这篇这样一个clipping threshold=0.1 贯穿所有任务表现还这么好)
1
Li X, Tramer F, Liang P, et al. Large language models can be strong differentially private learners[J]. arXiv preprint arXiv:2110.05679, 2021.
- 差分隐私会使模型无法捕获数据的尾部分布
1
Extracting Training Data from Large Language Models
成员推理攻击
数据增强仅用于提升准确性时,强度低,它无法实现对 MIA 的实质性保护
高强度的数据增强,例如裁剪图像的 90%,会降低准确性,但也会降低风险
流行的标签平滑机制通常会同时增加准确性与风险
准确率越高,风险越高
1
When Does Data Augmentation Help With Membership Inference Attacks?
分布之外的数据更不容易被成员推理
影子模型与训练模型同构,更容易实现攻击
越大的模型越容易被攻击
模型优化器影响不是很大
影子模型采用同样的数据增强会实现更好的攻击效果
数据增强会使的同一个样本在数据集重复出现,会有影响
1
Membership Inference Attacks From First principles
成员推理攻击在复杂的数据集上要有效得多(在复杂的数据上更容易过拟合)。模型反演、模型窃取则相反。
模型参数的白盒参数访问对于成员推理攻击没有帮助
1
ML-DOCTOR- Holistic Risk Assessment of Inference Attacks Against Machine Learning Models
神经网络模型架构越深,并不更容易受到攻击
具有高维输出(许多类)的任务比具有低维输出的任务更容易受到MIA的影响
过拟合不是成员推理攻击的决定性因素
所有在可推广模型上的实现中等或高成功率的黑匣子 MIA 都需要了解目标样本的真实类别
可推广性模型上的 MIA,对在模型参数有很大影响的记录上,如异常点或分布点,表现会更好
模型泛化能力很大程度上取决于所使用的优化器和正则化方法
优化器的选择对具有强背景信息的黑箱对手的可推广模型的潜在鲁棒性几乎没有影响
对于可推广的模型,唯一显著的差异出现在正确分类的样本和错误分类样本中间,而不是成员与非成员
1
SoK: Membership Inference is Harder Than Previously Thought
过拟合模型可以使用一些不典型方式来将该实例识别为训练集成员
MIA 攻击分为单次质询攻击(准确率、置信度、交叉熵、logits)与多次质询攻击(label only)。把成员推理攻击又称之为 metirc-based attack,很有意思的称呼,与我理解不谋而合。
模型对于训练数据周围的数据应该比测试数据周围的数据能够更正确分类
训练数据相较于测试数据距离分类边界应该远
模型应该会对训练数据的数据增强结果更加准确的分类
1
MemGuard: Defending against Black-Box MembershipInference Attacks via Adversarial Examples
对于 MIA 攻击效果的评估,应该考虑低假阳率(FPR)前提下的真阳率(TPR),这才是合理的评估指标,平均指标没有任何意义。对于样本的衡量,文章考虑了两个性质,一个是样本在模型中拟合的难易程度(通过loss可以判断,loss低代表容易拟合),二是样本对于模型的影响,通过对比有无该样本训练的模型对于样本的评估差别,如果没与差别代表样本对于模型影响不大,如果差别很大代表样本本身对模型影响很大。很多攻击只考虑了对于模型影响特别大的样本,而对于影响不大的样本它就没办法判断了。
通过引入 per-class hardness(用来衡量每个类训练的难易程度),没有有效提升低 FPR 下的攻击效果。
通过使用 per-example hardness(用来衡量每个样本训练的难易程度),有效提升低 FPR 下的攻击效果。
过拟合的模型更容易受到攻击,而且更准确的模型更容易受到攻击。
攻击模型与目标模型架构相同时,攻击效果最好,差别越小效果越好。
optimizer(SGD、SGDM、ADAM) 对于攻击效果没有影响。
如果影子模型数据增强方式与目标模型对应时,攻击效果最好。使用的数据增强越强,越难被攻击。
对于本攻击来说,白盒并没有什么改进。
1
Membership Inference Attacks From First Principles
文章提出成员样本与非成员样本可能最终 loss 差别不大,但是 loss trajectory(loss下降曲线)是不一样的。
蒸馏数据集越大,代表攻击者有更多的辅助数据集,效提升低 FPR 下的攻击效果。
1
Membership Inference Attacks by Exploiting Loss Trajectory
目标数据集中数据样本的分布对 FNR 的影响很小
训练集数据之间的距离越大,MA攻击概率越高
训练机数据之间的距离对 FNR 影响很小
两个数据集之间的差异越大,攻击成功率越高
两个数据集之间的差异距离对 MIA 的影响大于目标数据集数据间的距离
两个数据集之间的差异距离对 FNR 影响很小
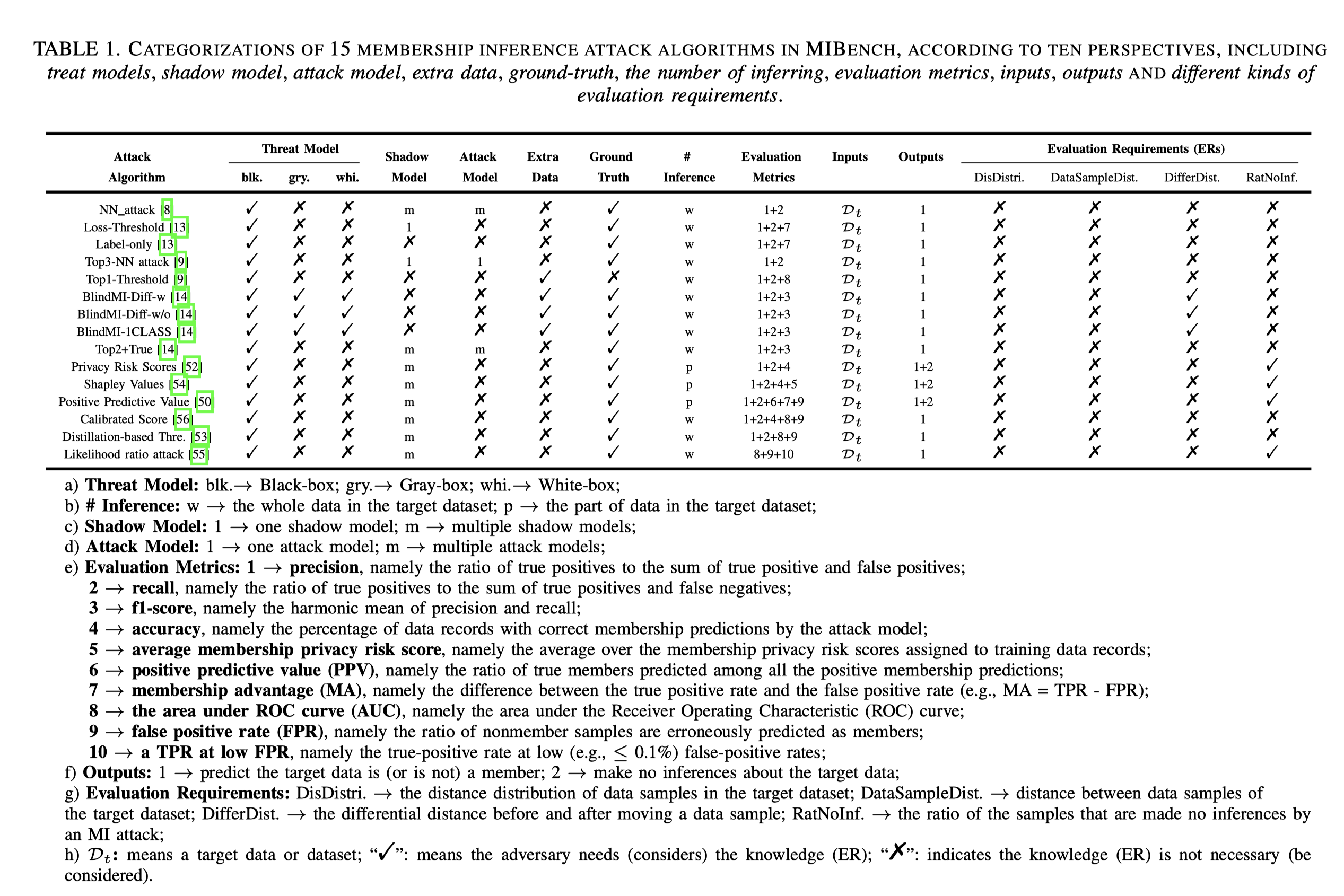
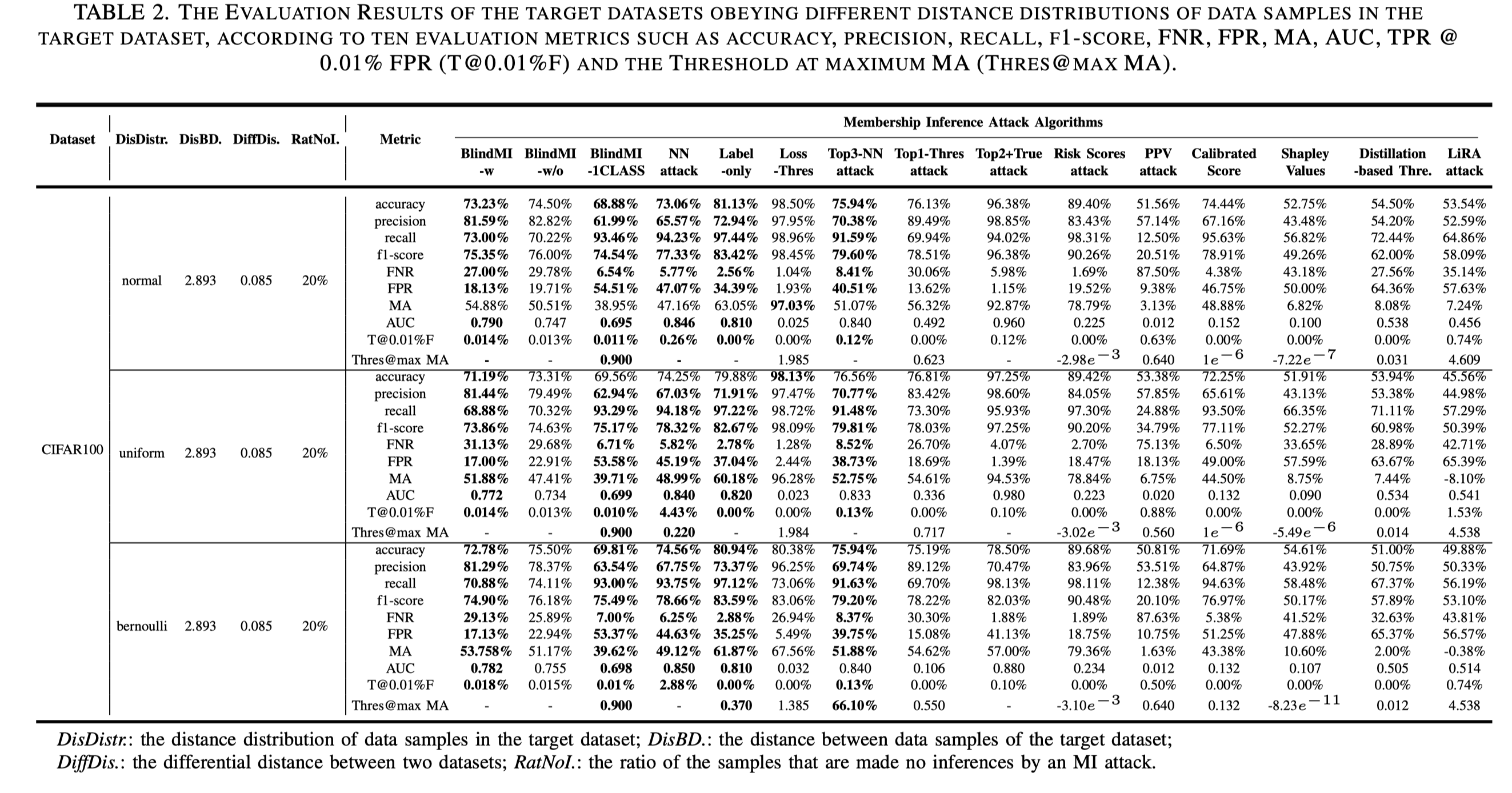
1
SoK: Comparing Different Membership Inference Attacks with a ComprehensiveBenchmark
文章提出了隐私洋葱理论,通过在特定的隐私攻击下删除最易受攻击的数据,并仅在以前安全的数据上重新训练模型,一组新的示例反过来也容易受到相同的隐私攻击
统计噪声、训练集大小的减少、重复训练示例的存在或模型的有限能力并不能解释洋葱效应。实验表明,洋葱效应可以用去除更极端的异常值后变为异常值的内部值来解释
工作表明,现有隐私审计缺乏“稳定性”,因为由于删除了一小部分训练数据,用户的经验隐私风险可能会发生显著变化。未来隐私审计应该随着底层数据变化而动态更新
也就是说 machine unlearning 会导致其他用户的隐私有更大的风险
1
The Privacy Onion Effect: Memorization is Relative
最小揭示隐私的攻击是成员推理攻击,模型反演攻击重构示例子集的代表性视图。模型反转攻击,重建训练数据点
与小模型和中模型比较困惑度策略通常会找到不常见的内容
转小写策略通常会找到有不规则大小写的内容,例如新闻标题(常常是大写单词)或错误日志 (很多大写单词)。
zlib 策略侧重于常见文本,比如新闻标题、许可证文件或重复的字符串
更大的模型会记住更多的训练数据
对于最大的语言模型,只需 33 次即可完全记忆。这意味着即使它仅在单个训练文档中重复多次,也存在记忆风险
1
Extracting Training Data from Large Language Models
神经网络训练
- 数据规模可以压制标签中存在的噪声
- 随着训练数据数量级的增加,任务性能呈对数上升
- 数据集是一个长尾分布(意思异常值与错误值以及非典型例子占大多数),而对于这些例子模型往往是采用记忆的方法也就是强行背下来的方法,但是这种记忆对于模型达到最优泛化能力是不可获取的
- 记忆得分高的例子是非典型例子和异常值/错误标记的例子的混合,经典例子的记忆得分往往更低
在受显著影响的测试示例中,大多数仅受单个训练示例的显著影响- 互相高影响的数据对,在视觉上有很强的相似性
- 对于成员推理攻击的防御,减少记忆会影响模型的准确度
- 在CIFAR-100上删除这两组中的964个独特训练示例可将测试精度降低2.46±0.36%,这与删除11000个随机示例的效果相当
- 记忆并不是只存在于最后一层
1
What Neural Networks Memorize and Why:Discovering the Long Tail via Influence Estimation
- 针对同样的数据集,采样不同的数据子集,同样的任务,异常点是会改变得,正常点大致相同
- 异常值包含的规律很傻,很难提取出规律,所以一般模型会直接记忆
- 更难提取的规律同样会在蒸馏过程中消失,小模型不会记忆太多异常值
- 提供了一个思路:查看哪些神经元(权重值)与小样本有关,一个神经元(权重值)被很多不同的规律激活,代表就会对多个前向传播的信号有作用;一个神经元(权重值)被激活的很少,代表对异常值有作用Can Neural Network Memorization Be Localized?
1
2
3
4
5
6```
14. 与需要更复杂表示的特征相比,神经网络对学习“简单”特征有很强的偏见
15. 数据集的长尾性质,ML 数据集中有大量的单例示例,特征在训练集中只出现一次,因此神经网络需要记住这些示例
16. 早期学习现象,表明更简单的示例是快速学习的
17. 错误标记的示例可能无法在模型的特定层学习,但它们确实对模型的所有层有很大的影响。对模型所有层的影响比干净的示例高一个数量级
18. 记忆分散在多个层SoK: Privacy-Preserving Data Synthesis1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2219. 当数据分布是长尾的时,从分布的尾部记忆样本可以帮助模型泛化。
20. 记忆不能简化为过度拟合;事实上,记忆和过度拟合是不同的现象。
21. 许多深度神经网络具有足够的记忆能力来拟合完全随机输入输出关联的大数据集。
22. 记忆可以通过影响估计技术有效地测量,但需要特别注意确保此类估计是准确的。
23. 特别是对于生成模型,通常很难概念化模型记忆的内容(即是否产生与训练记录计数“相似”的输出作为记忆?)评估这一点的一种直观方法是故意插入数据样本,这些样本“预期”被模型记忆,因为它们的“典型性”。然后,根据模型如何再现这些输入作为输出(即生成模型)或这些数据点的性能与数据集其余部分的性能(例如监督学习)相比,测量记忆的能力。
24. 对抗样本是人为非典型的,因此对模型的影响更大(恶意或其他)
25. 越来越多的证据表明,对 ML 的隐私攻击对被记忆的样本更有效。
26. 生成模型中的记忆可以通过自我影响或模型生成与输入数据相似的输出的能力来感知。
27. 如果样本没有再次遇到,则在训练过程中可能会被遗忘。
28. 遗忘可以被人为地诱导为“记住”单个数据点。
29. 差分私有 ML 训练(可证明)可以防止记忆引起的负面特征。
#### 隐私数据合成
1. 数据合成领域主要包括 表格数据(Tabular data)、轨迹数据(Trajectory data)、图数据(Graph data)
2. 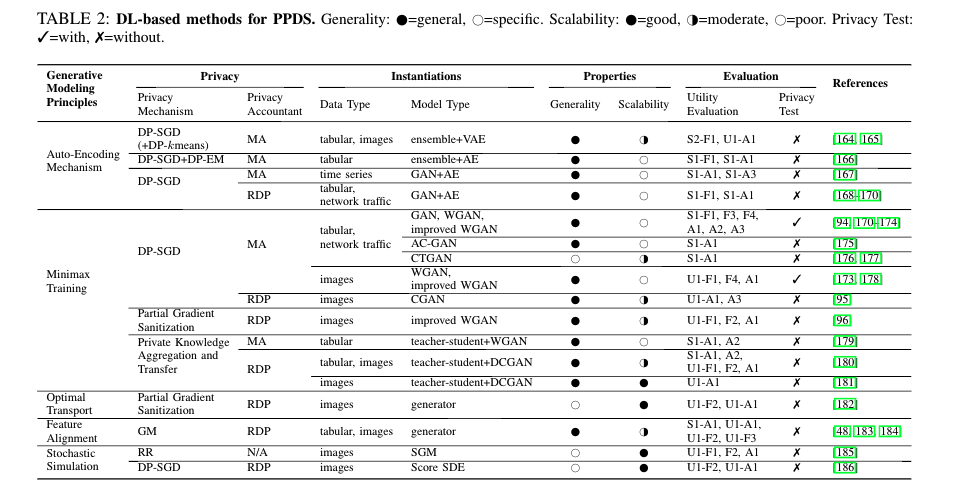
3. 对于合成数据方法可以做的工作
* 隐私攻击:文章认为常见的成员推理攻击本身就是针对 logits 等信息,而在数据合成领域应该有更多的信息可以利用
* 隐私度量:这是隐私领域通用的一个难题,如何去提出一个通用型隐私量化标准
* 威胁模型:去研究是否有更合理的威胁模型假设,放宽隐私限制(类似于 label DP)
* 公平性问题研究:针对合成数据对于不具有代表性的分类可能会有公平性问题解决方案设计ProPILE: Probing Privacy Leakage in Large Language Models1
2
3
4
5
#### 大模型 PII 隐私
1. 训练数据中包含的不同类型的 PII 的很大一部分可以通过战略制作的提示披露
2. 通过细化提示,可以访问模型参数,并为 LLM 利用几百个训练数据点,显著放大 PII 泄漏的程度
```
数据蒸馏
数据蒸馏方法分类
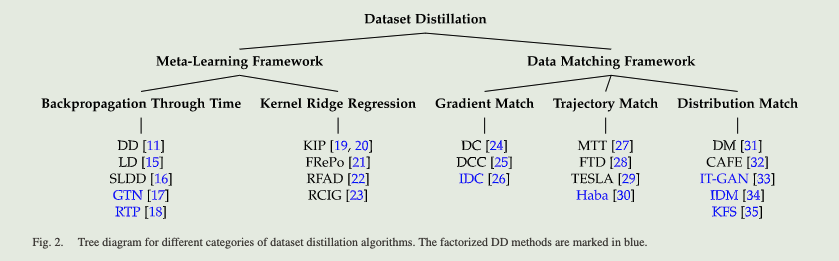
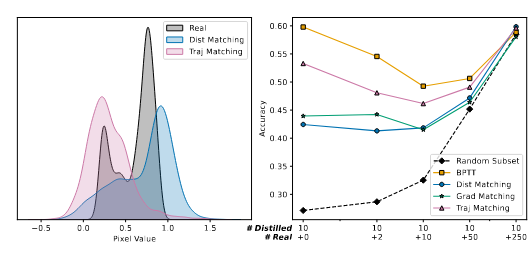
当前蒸馏数据无法替代真实数据,其中存在一个限制使用一种模型架构提取的数据不能有效地用于训练不同的模型架构。
将真实数据样本添加到蒸馏数据中可能会降低训练模型的准确性。